측정된 성능과 전력은 32비트 산업용 MCU가 실제 배포 제약 조건을 충족하는지 여부를 결정합니다. 체계적인 전력 프로필과 결합된 벤치마크 제품군은 와트당 컴퓨팅, I/O 병목 현상 및 네트워킹 실행 가능성을 보여줍니다. 이 기사에서는 제어된 CPU/메모리/I/O 벤치마크, 반복 가능한 전력 측정, 이더넷 및 DMA 처리량 테스트, 실제 조정 권장 사항XMC4800E196K2048AAXQMA1의엔지니어링 트레이드오프 및 배치 선택을 안내합니다.
소개 (데이터 연동 후크-문장 10-15%)
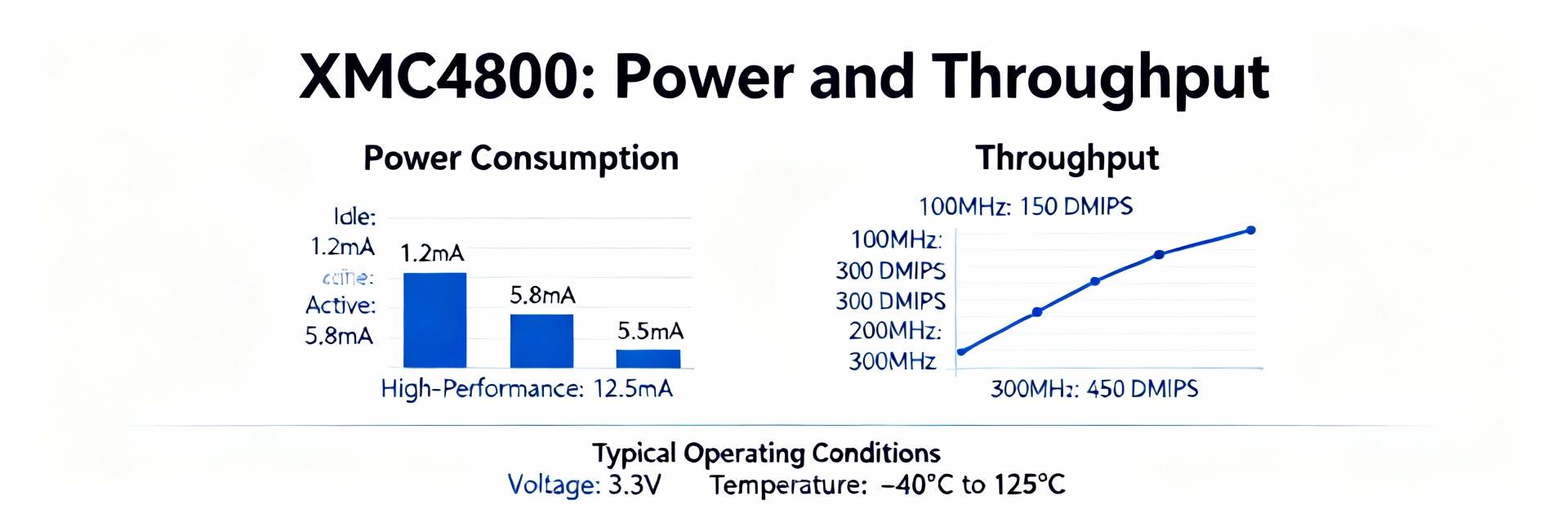
요점: 엔지니어는 MCU를 센서 집계, 프로토콜 브리징 또는 에지 컴퓨팅 역할에 적용하기 전에 수치 증거가 필요합니다. 증거: CoreMark/Dhrystone, memcpy 마이크로 벤치마크, DMA 및 이더넷 패킷 테스트, 마이크로 앰프 절전 프로파일링의 조합으로 완전한 뷰를 제공합니다. 설명: 이 기사에서는 팀이 실제 워크로드에서 대기 시간, MB/s 및 microjoules-per-operation을 평가할 수 있도록 제어된 테스트, 측정 모범 사례 및 결과 해석을 개략적으로 설명합니다.XMC4800E196K2048AAXQMA1의.
배경 및 주요 사양 (배경)
주요 사양(플래시, SRAM, 최대 시계, ADC 채널, I/O, 패키지)
점: 주요 하드웨어 제한은 벤치마크 천장과 전력 포포장모양을 제한합니다.증거: 코어, 플래시, SRAM, 클로크 및 주변 카운트는 달성 가능한 코어 마크 / MHz, DMA 분쟁 및 ADC 샘플링 처리량을 결정합니다.설명: 아래의 컴팩트 테이블은 테스트 설계 중에 빠른 참조를 위해 CPU, 메모리 지연 및 주변 처리량에 직접 영향을 미치는 매개 변수를 강조합니다.
| 사양 | 가치 (일반적) | 임팩트 |
|---|---|---|
| 플래시 | 2048 KB | 플래시 대기 상태는 코드 가져오기 지연 및 브랜치 중량 워크로드에 영향을 미칩니다. |
| SRAM은 | ~352 KB (포장) | 큰 버퍼를 허용하고 외부 메모리 트래픽을 줄입니다. |
| 최대 CPU 시계 | 최대 144MHz(장치 데이터시트) | I/O 바인딩되지 않는 한 CoreMark 및 처리량을 직접 확장 |
| 코어 | FPU가 있는 Cortex M4 | FPU는 FP 커널 처리량을 향상시키고 사이클 수를 줄입니다 |
| DMA는 | 여러 채널 | memcpy와 주변 기기 버스트에 대한 제로-CPU 전송을 가능하게 합니다 |
| 통신 | 이더넷, SPI, UART, CAN | 네트워킹 및 주변 장치의 스트레스 한도 결정 |
성능에 영향을 미치는 아키텍처 강조 사항
요점: 아키텍처 기능은 마이크로 벤치마크에서 관찰 가능한 병목 현상을 설정합니다. 증거: FPU, 버스 매트릭스, DMA 엔진, 플래시 프리페치/가속 변경 주기/op 및 지연 시간의 존재. 설명: FPU는 부동 소수점 커널에 대해 큰 승리를 가져옵니다. 멀티 마스터 버스와 별도의 주변 DMA는 CPU 스톨을 줄입니다. 플래시 대기 상태 또는 캐시 부재로 인해 명령 가져오기 지연 시간이 증가하고 중요 코드가 SRAM으로 재배치되지 않는 한
벤치마크 방법론 및 테스트 설정 (데이터 분석)
테스트 환경과 반복성
점: 반복 가능한 측정은 제어된 하드웨어, 펌웨어, 및 로깅이 필요합니다. 증거: 표준 평가 보드 또는 잘 특성화된 콤파일러를 사용하고, 측정 전류를 교정된 전류 전송기+ADC 또는 하이사이드 계측기를 통해 측정하고, 스코프/전류 탐지기로 임시 동작을 캡처합니다. 설명: 클럭 설정, 컴파일러 최적화, 및 빌드 플래그를 잠금; 주변 온도 및 전력 전선 필터링을 기록; 워밍업 사이클을 실행; 타임스탬프, 테스트 ID, 및 평균화된 샘플과 함께 결과를 CSV로 로그를 기록하여 여러 실행 간 통계적 유효성을 보장합니다.
작업 부하, 벤치마크 및 측정된 지표
포인트: 대표적인 세트는 CPU, 메모리, 인터럽트, 그리고 I/O 행동을 포착합니다. 증거: CoreMark과 Dhrystone을 결합하여 CPU 기준선을 설정하고, 정수/FP 커널과 memcpy를 메모리로 사용하며, 실시간 제약을 위한 인터럽트 지연 시험을 하고, DMA, SPI/UART 버스트와 이더넷 패킷 스트림을 I/O로 사용합니다. 설명: CoreMark/MHz, Dhrystone DMIPS, 사이클/오퍼레이션, 마이크로초 단위의 지연 시간, DMA/이더넷 MB/s, 그리고 마이크로조 단위의 오퍼레이션당 에너지를 포착하여 플랫폼 간 정규화와 에너지 효율 비교를 가능하게 합니다.
CPU, Memory & I/O 성능 테스트 결과 (데이터 분석)
CPU 성능: CoreMark / Dhrystone 결과 해석
요점: 원래 CoreMark 숫자는 실제 CPU 기능을 나타내기 위해 정규화되어야 합니다. 증거: 기존 증거CoreMark/MHz 옆에 CoreMark 를 표시하고 사용된 플래시 대기 상태와 클럭 설정을 보고합니다. 해명Ion: 클럭 속도와 플래시 대기 상태를 표준화하여 파이프라인 또는 메모리 정지를 식별합니다. 주의하다분기가 많은 코드는 플래시 추출 지연에 의해 제한될 수 있습니다. 즉, 핫 사이클을 SRAM 에 재배치하거나 ACC 를 활성화합니다리프팅 모드는 일반적으로 표준화 점수를 크게 높입니다.
메모리 및 I/O 처리량: RAM 대역폭, DMA 및 주변 스트레스
포인트: 메모리 및 주변 처리량은 지속적인 데이터 이동 성능을 정의합니다. 증거: 다양한 전송 크기에 대한 memcpy 처리량, 동시 CPU 부하에서 DMA 지속 MB/s 및 SPI/UART의 주변 버스트 속도를 측정합니다. 설명: DMA가 CPU 기반 전송을 능가하는 교차 지점을 찾기 위한 차트 처리량 대 전송 크기, 전송 중 CPU 활용률을 기록하여 데이터를 이동하는 동안 애플리케이션 처리를 위한 헤드룸을 표시합니다.
전력 소비 및 효율성 분석(방법 가이드)
활성, 유휴 및 저전력 모드 측정
포인트: 모드별 전력 분석은 사용 가능한 에너지 절감을 드러냅니다. 증거: 샘플 전부하 활성(최대 클럭+주변기기), 클럭 차단된 대기, 심한 수면 모드; 측정된 전류와 전압으로 계산한 처리 전력(mW)을 안정적인 창간에 걸쳐 평균 내릅니다. 설명: 단일 샷 스냅샷을 피하십시오—반복된 사이클을 통해 평균 내고 전환을 포착하십시오; 측정 해상도와 샘플링 방법을 기록하십시오; 전류, 전압, 계산된 전력을 위한 표 템플릿을 제공하여 비교 가능한 보고서를 보장하십시오.
| 모드 | 현재 (mA) | 전압 (V) | 파워 (mW) |
|---|---|---|---|
| 활성 (최대) | — | - | — |
| 유휴 | — | — | — |
| 깊은 수면 | — | — | — |
Energy-per-operation및 트레이드오프(전력 대 성능)
요점: 운영당 에너지는 전력 및 지연 시간 트레이드오프를 통합합니다. 증거: E = 전력 × 운영당 시간을 계산하고 클럭 또는 DVFS를 쓸면서 에너지 대 처리량을 표시합니다(사용 가능한 경우). 설명: 클럭을 낮추면 절대 전력이 감소하는 경우가 많지만 실행 시간이 전력 감소보다 증가하면 작업당 에너지가 증가할 수 있습니다. 실제 팁에는 DMA 사용, I/O 배치, 작업당 에너지 최소화를
처리량 테스트: 이더넷, DMA 및 실제 사례 연구(사례 연구 + 방법)
Ethernet & 네트워킹 투사량 테스트 계획 및 해석
포인트: 네트워킹 테스트는 프로토콜과 CPU 오버헤드를 분리해야 합니다. 증거: 다양한 패킷 크기로 TCP/UDP 스트림을 실행하고, 인터럽트 기반과 제로캡처 방법을 교대로 사용하며, 패킷 손실, 지터, 그리고 Mbps당 CPU 오버헤드를 측정합니다. 설명: 투하율 대 패킷 크기와 CPU 부하 대 투하율을 제시하여 인터럽트 또는 버퍼 처리가 CPU 제한이 되는 지점을 식별합니다; 패킷당 CPU 사이클을 정량화하여 버퍼 크기 조정과 인터럽트 결합을 안내합니다.
미니 케이스 스터디 + 배포 체크리스트 (실제 세계 튜닝)
포인트: 실용적인 튜닝은 처리량과 효율성에 측정 가능한 이점을 제공합니다. 증거: 센서 집계 게이트웨이 예를 들어, 우선순위 DMA 채널을 적용하고, 인터럽트를 그룹화하고, 버퍼 크기를 조정하면 지속적인 MB/s가 증가하고 CPU 부하가 감소했습니다. 설명: 배포 체크리스트 — 안정적인 스트림을 DMA로 이동시키는 것을 우선시하십시오, 지연 시간이 민감한 코드를 SRAM에 배치하십시오, 주변 장치 배치를 활성화하십시오, 적절한 수면 모드를 선택하십시오, 그리고 CPU, 메모리 및 현재를 런타임 모니터링하여 현장에서의 회복을 감지하십시오.
요약 및 실행 가능한 핵심 내용 (기사의 10-15%)
Point: 측정된 강점과 제약조건은 통합 선택을 안내합니다.XMC4800E196K2048AAXQMA1의증거: 테스트는 SRAM 및 FPU 가속화 수학에 뜨거운 코드가 있을 때 강한 DMA 지원 처리량과 와트당 고체 컴퓨팅을 보여줍니다.설명: 엔지니어들은 먼저 경량 CoreMark 플러스 memcpy 및 DMA 처리량 테스트를 실행한 다음 우선순위 DMA, 버퍼 튜닝 및 인터설설설설트 그룹화를 적용하여 사용할 수 있는 이더넷 및 I/O 성능을 달성해야 합니다.
- CoreMark 및 memcpy microbenchmarks를 먼저 실행하여 기본 CoreMark/MHz 및 RAM 대역폭을 설정합니다.이 숫자는 원시 컴퓨팅과 데이터 이동 헤드룸을 예측합니다.XMC4800E196K2048AAXQMA1의.
- DMA를 사용하여 지속적인 전송을 수행하고 지연에 민감한 루프를 RAM으로 이동시켜 플래시-스탑 효과를 줄이고 실제 중단에 따른 정규화된 처리량을 향상시킨다.
- 운영당たり의 에너지를 측정하여 클럭 감소와 실행 시간 증가를 균형을 맞추세요; 배치 I/O를 수행하고 깨어나는 횟수를 줄여 배터리 제약된 배포 환경에서 μJ/op을 낮추세요.
FAQ는
첫 번째 비교 평가를 위해 어떤 벤치마크를 실행해야 할까요?
고정 클럭의 CoreMark와 CPU 기준선 및 RAM 대역폭을 캡처하는 작은 memcpy 마이크로 벤치마크로 시작하십시오. 이 두 가지 빠른 테스트는 장치가 CPU인지 메모리 바인딩인지 여부를 밝히고 추가 프로파일링을 위해 코드 재배치, DMA 또는 클럭 튜닝의 우선 순위를 지정할지 여부를 안내합니다.
반복 가능한 결과를 위해 어떻게 전력을 측정해야 합니까?
보정된 션트 저항기와 샘플링된 ADC 또는 하이사이드 파워 미터를 사용하고, 여러 번의 실행에서 평균을 사용하고, 웨이크업을 프로파일링할 때 오실로스코프를 사용하여 과도를 캡처합니다. 주변 조건, 레일 디커플링 및 샘플링 해상도를 기록하여 설정 간에 측정이 비교되도록 합니다.
어떤 조정이 가장 큰 처리량 이익을 제공합니까?
이더넷 패킷 버스트와 일치하도록 정상 상태 전송을 DMA로 이동하고 버퍼 크기를 조정하면 일반적으로 애플리케이션 로직을 위한 CPU를 확보하면서 가장 큰 지속적인 MB/s 개선을 제공합니다. 이를 인터럽트 병합 및 SRAM에 핫 루프 배치와 결합하여 최상의 결과를 얻으십시오.
